bitmap,这个词在许多开发场景中都会出现,比如安卓原生开发中Bitmap用于存储位图图片,但这里我们说到的bitmap是指更常见的一个数据结构,将数据按照某种规则(比如整数按照索引位置)映射到某个bit位,从而使用紧凑的bit结构记录大规模数据集合的数据状态。
bitmap的一大特点是适合的是记录大规模整数的有无状态:每个bit存储一条整数的有无状态,bitmap这一紧凑的结构就能使用极少的空间完成大量整数的状态的记录,进行快捷的查找、排序和统计。而bit为单位的存储又将带来位运算上便捷的交、并等集合运算,多个bitmap之间便捷的交、并等集合运算,在索引、标签存储等场景又极适合,我们将在另一篇文章中尝试给出一个示例。
bitmap用于大规模整数的查找、排序和统计
假如存在一个至多有(2^31-1)个的正整数的集合,范围为0-(2^31-1),给出一个正整数,如何判断这个正整数是否在集合中?
以java为例。简单粗暴的方式,建一个Set/Map记录状态?或者优化下,利用下先天条件:正整数,建立一个大小为2^31的int数组(且不论JVM实现是否能够支持创建2^31长度的数组,读过ArrayList源码的我们都知道,最大数组长度可以设置为2^31 - 8,因为“Some VMs reserve some header words in an array.”),在java中int占用4字节,那么仅存储这一数组就需要开辟出一段 4*(2^31) Byte = 2^33 Byte = 2^23 KB = 2^13 MB = 2^3 GB = 8GB的内存空间。这不是一个很现实的实现方式。
利用下bitmap,我们建立一个大小为2^31的bit数组,那么仅占用了2^31 bit = 2^28 Byte = 2^18 KB = 2^8 MB = 256 MB的空间,就可以完成所有范围内整数有无的标记。
在使用bitmap进行存储的同时,bitmap除了标记数据的有无进行查找,还将额外的带来一些功能。比如排序。我们在上例中增加一个限制:所有整数是不重复的。那么对这一数据集合进行排序最高效的手段就是使用bitmap存储,然后按照bitmap顺序遍历,即得到了排序后的数据集合——这其实就是计数排序,不过对大规模数据的情况做了针对性的牺牲和优化:牺牲了通用性(约定不重复的数据),带来了大规模数据下的空间优化。
但是回看这个场景,又可以发现bitmap的问题。
因为无法预知数据的实际范围,bitmap必须开辟出足以容纳最大数据范围的空间,比如上例,就需要开辟出2^31大小的bitmap —— 即使实际数据是相当稀疏的,如只有两条数据:0和2^31,因此数据稀疏时bitmap会浪费一部分空间,数据越稀疏浪费越大。对于已确定数据范围的数据集合,我们可以稍加改进,比如明确范围是2^20到2^21时,那么我们可以将2^20映射到bitmap的首个bit,向后延伸——这将对bitmap的存储浪费稍有优化,但并不是什么新的特性,只是一点小tips让bitmap总能恰好装下范围内的数据,决定存储空间利用率的归根到底还是数据稀疏度。
因为使用bit来标记数据状态,每个bit仅可表示有/无 —— 也因此,上例中我们只能做到记录数据的有无用于查找,但是对于重复的数字,无法记录其出现次数。如何记录出现次数呢?很简单,我们可以联用多个bitmap组成阵列,每个bitmap存取状态值其中一个bit,如此联用即可,但是需要的存储空间相应增加。或者造个曲线救国的轮子:我们使用两个相邻的bit作为一个整体单元,那么每个单元就可以标记出四种状态,那么就可以约定比如:00-不存在、01-出现一次、10-出现多次。但这样bitmap在高效存储上的优势就被削弱了,上例的场景我们不得不开辟 2*(2^31) bit 大小的bitmap。这一方式与多个bitmap联用相比,实现上更复杂,空间最大可能占用上其实也并没有优化,只是一个并不成熟的轮子而已。
bitmap的实现
JDK BitSet
JDK标准包提供了bitmap的实现类BitSet,使用bit位记录索引位置数据的状态,并且空间可以根据需要自动增加。
BitSet提供的and/andNot/or等操作都是原地修改的。
高效的压缩bitmap——RoaringBitmap
RoaringBitmap,github地址在这里,使用分桶的方式优化bitmap在数据稀疏情况下的空间占用:将32位无符号整数按照高16位分桶,即最多可能有2^16=65536个桶,称为container;在存储数据时,根据数据的高16位创建/使用对应的container,再将数据的低16位放入container下的存储中,具体container内的存储将根据数据条数选用short[]或者bitmap实现。如此,通过分桶只为必要范围内的数据开辟了存储空间。
关于RoaringBitmap的实现细节网上优秀的文章可学习的太多,本人不敢再去赘述。
redis的bitmap
redis提供了setbit/getbit命令,来设置/查询一个ASICC编码的字符串(每个字符占8bit)的指定位置bit的值,相当于提供了一个bitmap的实现(Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type which is treated like a bit vector. Since strings are binary safe blobs and their maximum length is 512 MB, they are suitable to set up to 2^32 different bits.)
1 | 增加一个key bitmapkey,对应value为hello |
在redisson中提供了封装类RBitSet,用于操作bitmap
自定义实现bitmap
我们使用java实现一个简单的bitmap,它使用一个 (2^31 - 8)bit 大小的空间支持大规模整数的查找、排序和统计,可以指定起始值和结束值以切换允许的数据范围,并且可以指定单个存储单元占用的bit位数,以支持扩展更多数据状态。
如上所属,只是一个并不好的轮子而已
布隆过滤器BloomFilter
我们跳脱出来看,其实bitmap就是一个特殊的哈希表:key为存储的值,value为值的状态(有无,或者通过增加单个key映射到的bit数量扩展到更多状态);在上文示例里,我们使用bitmap存储正整数的状态时,把正整数映射到bit数组的索引,或者把2^20映射到bitmap的首个bit的方案,都可以称之为一个hash,hash实现分别为:index = val 及 index = val - 2^20 ,只不过特殊的是:因为开辟了至少和数据范围一一对应的空间,有了足够的输出空间,不会产生哈希冲突。
有了这样的理解,我们就不难想到,通过构造合理的hash函数,我们可以使用bitmap标识任意数据的状态——而不是像上文一样限定在了一定范围的正整数。
这一思路就是BF的基本原理:使用hash计算出数据在bitmap中的索引位置,在该位置的bit记录这一数据的状态;查找某一条数据的状态时,使用hash计算出数据在bitmap中的索引位置,查询这一位置的bit记录,判断数据状态。
实际的场景中,存储空间是有限的,而要存储的数据是无限的(至少是远远大于存储空间的),那么再优秀的hash函数也会冲突,这就导致了BF准确性上的问题:如上的基本原理介绍中,查找某一条数据的状态时,hash计算得到的索引值如果存在冲突,那么就会似有实无。
所以在实际的BF实现中,一般会引入误判率的参数,使用一系列随机hash函数来控制冲突概率从而控制误判率,具体可以参考下文介绍的guava的BF实现。
绕开误判的问题,我们继续思考,就发现了BF的另一个问题:难以进行删除操作。为何?因为哈希冲突的存在,无法确定元素是否真实存在,无法保证一个bit记录的数据只有一条,那么就无法进行删除操作了。解释太绕口,举一个例子:假如hash= n%7,记录了元素8和15,那么BF(8)和BF(15)的index均为1,这种情况下如何删除元素8?
因此BF的基本特点是:应用于大规模数据状态高效存储和快速查找,但是存在误判可能(似有实无),难以进行删除操作。
guava的BloomFilter
guava提供了BloomFilter的实现,可以声明BF最容量和误判率来进行初始化。
为何可以控制误判率呢?这就需要提到guava的BF中hash的实现策略,看下是如何减少哈希冲突、控制误判率的。
guava的BF中引入n个不同的hash函数;在新增元素时,使用n个hash函数计算出多个索引位置,将这些索引位置的bit均置为1;查询某个元素是否存在时,同样使用n个hash函数计算出对应的所有索引位置,检查这些bit的值,全为1时才认为元素存在。在这里有一个BF的js实现,提供了对这一操作的演示动画,可以方便理解。
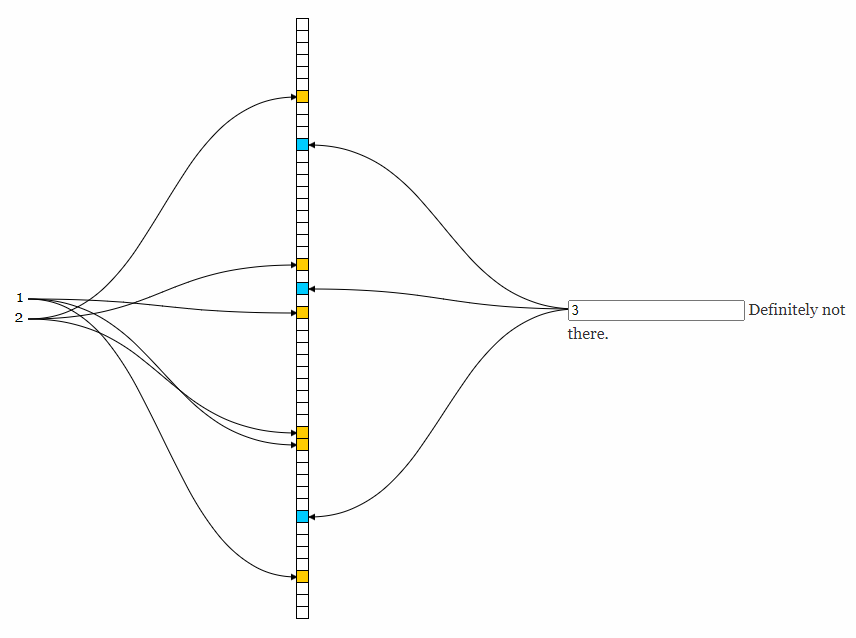
我们可以做一个模拟的计算,假设每个hash函数的冲突概率都是0.1,那么两个不同的元素在n个hash函数都出现冲突时的概率是0.1^n,这种情况才会引起两个元素之间的误判,所以只要调整hash函数的选型和数量就能控制冲突概率从而控制误判率。
插入一提,guava的BF实现使用了MurmurHash算法,一种驰名已久的高性能、低冲突的hash算法。
redis的BloomFilter
使用BF记录数据状态时,分布式场景下如何处理?上文介绍了redis提供的bitmap能力,那么其实只要解决了hash函数问题、将任意数据映射到bit,就实现了一个BF。
不过虽说程序员喜欢造轮子,倒也不必啥也造,有现成的好方案自己还硬造,造出来也没现有的优秀,那作为练手的娱乐还行,当真用就不是什么好选择了。
基于redis的bitmap实现BF的工具不少,比如redisson这一redis客户端,项目中完全可以使用
关于Cuckoo Filter(布谷过滤器)
上文我们分析到,BloomFilter不适用删除操作,而Cuckoo Filter对这一点进行了改进。
(后续补充)